
The Most Crucial Component in an ML Pipeline is Invisible
The process of building and training machine learning models is always in the spotlight. There is a lot of talk about different Neural Network architectures, or new frameworks, facilitating the idea-to-implementation transition.
Moreover, many developers are putting a lot of effort into developing tools that take care of the peripherals: data management and validation, resource management, service infrastructure, the list goes on.

Despite the AI craze, most projects never make it to production. In 2015, Google published a seminal paper called the Hidden Technical Debt in Machine Learning Systems. If you’ve been involved in ML, you have already seen the figure below.
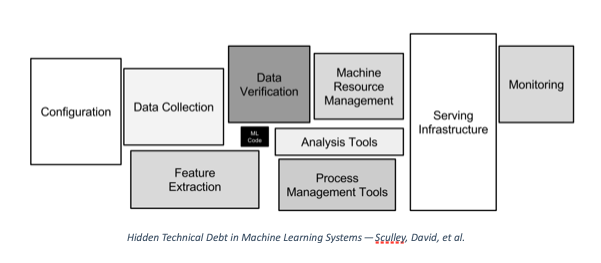
In this work, the authors warn that it is dangerous to focus only on the powerful ML tools available today and take them for granted. “Using the software engineering framework of technical debt, we find it is common to incur massive ongoing maintenance costs in real-world ML systems,” the authors write.
There are many components in an end-to-end ML system, and each has an important role to play. Data collection and validation provide the machine’s ‘oil,’ feature extraction is the filtration system, serving infrastructure the actual service and monitoring is the engine’s real-time overview.
The model itself is the heart of an ML engine, and other components of the pipeline are the vital organs. However, the circulatory system, the circuit that connects everything and enables nutrients to move around is often overlooked. But what comprises this system?
Today, we talk about a box that is not present in the figure above: the metadata store. This component works silently in the background, gathering information and providing the glue to bind everything together. This is the most crucial element in an ML pipeline, and it’s nearly invisible.
ML Metadata
What is a metadata store, and why is it important? It is a database for recording and retrieving metadata associated with ML workflows. What were the inputs to a pipeline step? What artifacts did the step produce? Where do they live? What is their type?
Below, we look at a specific metadata store implementation: the ML metadata (MLMD) library by Google. MLMD is an integral part of TensorFlow Extended (TFX) and a stand-alone application, which can be used independently of whichever ML framework one chooses to use. This example will help us better understand the need for such a component.
The MLMD library
MLMD helps us analyze all the parts of an ML pipeline and how they interconnect instead of looking at the components in isolation. It provides the complete lineage of every event that happened, and, most importantly, the entire history of our model.
Among other things, MLMD can help us identify:
- Which dataset did the model train on?
- What were the hyperparameters used to train the model?
- What were the metrics of the model?
- Which pipeline run created the model?
- Have we trained any other model using this dataset?
- How do the different models compare?
- Which version of a specific ML framework created this model?
MLMD needs a database to store the information and dependencies of every step. To this end, it exposes an API to perform the necessary operations on several entities in a SQL database. Note that MLMD supports SQLite and MySQL. However, in most cases, you won’t ever care about the DBMS that is running underneath.
The most important entities created and stored by MLMD are:
- Artifacts that are generated by the pipeline steps (e.g., the trained model).
- Metadata about the executions (e.g., the step itself).
- Metadata about the context (e.g., the whole pipeline).
MLMD in Action
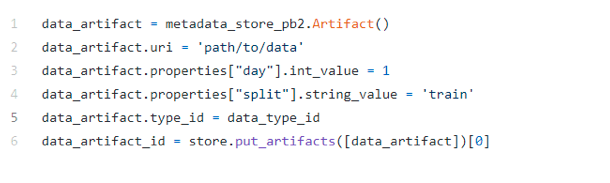
Let’s now look at a typical ML workflow and how to integrate MLMD into the pipeline steps. Initially, we need to create two artifacts: one representing the dataset and one for the model. To this end, we should register the relevant artifact types first. Think of it like this: the ArtifactType is the class, and the Artifact is the object.

Let’s examine the ArtifactType representing the dataset: in our declaration, we specify that each dataset Artifact should have two custom properties: a day and a split. Similarly, the model Artifact has a version and a name.
On top of that, other properties are passed directly to every Artifact. Think of it as the inheritance properties in object-oriented programming. For example, each Artifact should have a URI pointing to the physical object. Now that we have the ArtifactType, let’s create an Artifact for the dataset.
Next, let’s create an ExecutionType and the corresponding Execution object tracking our pipeline’s steps. Let’s create a trainer execution object to represent the training step, and set its status to running.

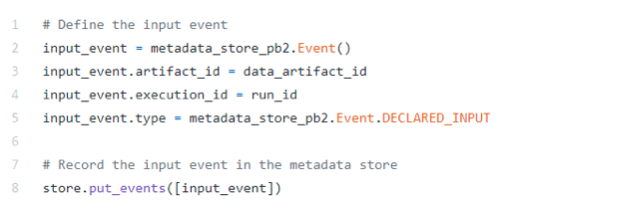
Now, we would like to specify that the dataset Artifact we created before is an input to the Execution step named “Trainer.” We can do that by declaring an Event entity.
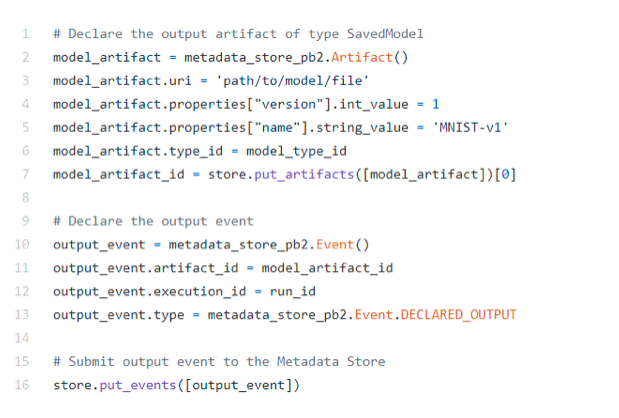
When the training step is completed, it produces a model. Let’s define a model Artifact and set it as an output to the Execution step “Trainer.”
Finally, the “Trainer” step is completed, and we can set its status to “Completed.”

To get the whole picture, let’s bind everything together and record our model Artifact’s complete lineage, using Attributions and Assertions entities.

These ~23 lines of code create a Context entity for the experiment and link the “Trainer” as an Execution step of the experiment and the model as its output. That’s all; MLMD takes care of the rest, so you will be able to track everything as we saw in the first section.
The Benefits of Using KALE
KALE (Kubeflow Automated pipeLines Engine) is an open-source ML workflow tool, which simplifies the data scientist’s experience with Kubeflow and Kubernetes. It comes with built-in support for MLMD, and it can automate the whole process described above.
When starting a new Run (e.g., pipeline), Kale automatically registers it as a new context. Each step of the pipeline submits itself as an execution, providing several pieces of information, like its name, state and runtime details (e.g., the pod’s name, namespace, etc.).
Moreover, Kale can automatically record the outputs of each step as Artifacts and use Events, Attributions and Associations to connect everything together. In the end, the user can explore the lineage of every artifact created by Kale in the metadata UI.
While the training code is the heart of an ML engine, the circulatory system which connects everything is often missing. There are many components in an end-to-end ML system, and each has an important role to play.
However, today we talked about a component that works silently in the background and provides the glue that binds everything together—the metadata store.
We saw how MLMD implements this idea, its core concepts and how we could use it in a simple ML setting. To get started, see the installation instructions here. However, you won’t see its full potential just by installing it locally. Instead, it is better to use it in a complete and cloud-native environment with Kubeflow. Thus, I would suggest using MiniKF, which includes Kubeflow, Kale and Rok all in a single-node instance that can be deployed on a laptop or any cloud environment.
To see a real-world example and experience the power of KALE with MLMD, follow the steps in this codelab.
