
IBM revealed today at the KubeCon + CloudNativeCon North America conference that it is making the ModelMesh tool that enables multiple machine learning models to share a container available as open source software.
At the same time, IBM revealed it is melding ModelMesh with Kserve, open source software based on the Kubernetes Custom Resource Definition for serving machine learning (ML) models on machine learning frameworks such as Tensorflow, XGBoost, ScikitLearn, PyTorch and ONNX.
ModelMesh was created to provide a model-serving management layer for the portfolio of Watson tools IBM makes available to build artificial intelligence (AI) applications. Deployed on top of a Kubernetes cluster, ModelMesh loads and unloads AI models to and from memory to optimize the overall IT environment by automatically determining when and where to load and unload copies of the models based on usage and current request volumes. ModelMesh also acts as a router that balances inference requests between all copies of the target model.
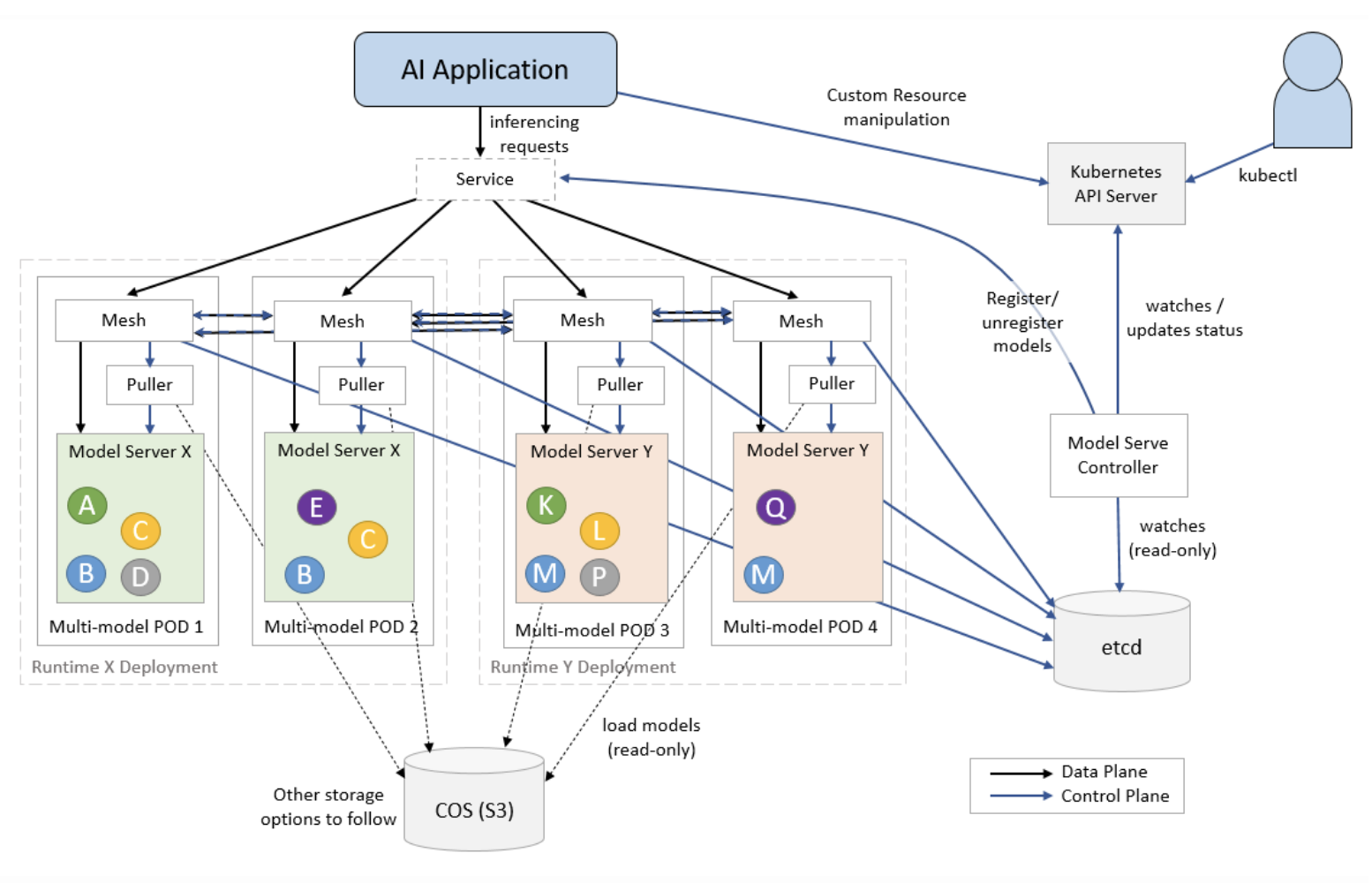
Animesh Singh, CTO for the Watson Data and AI Open Source Platform at IBM, says the issue that ModelMesh addresses is that most IT organizations today assume they can only include one model per container. While there are some models that are too large to share a container, Singh notes there are plenty of AI models that are only several kilobytes in size. ModelMesh makes it possible to both maximize IT infrastructure resources as well as overcome the limitation created by the number of pods that organizations are allowed to create per Kubernetes cluster, notes Singh.
Kubernetes has quickly emerged as the de facto standard for building AI applications, especially those that rely on containers to create modules that would otherwise be too unwieldy. However, as organizations start to build and deploy hundreds, sometime even thousands of machine learning models, they are starting to encounter scaling issues. IBM created ModelMesh to address those issues on the IBM Cloud. Now, that capability is being made available as open source software that data science teams can employ anywhere.
The challenge, of course, is incorporating models within those applications. There is almost no application being built today that won’t incorporate some level of AI. However, AI models are built by data scientists that use a wide range of machine learning operations (MLOps) platforms to construct them. The pace at which those AI models are developed, deployed and updated vary widely, but the one issue that all organizations need to address going forward will be how to insert AI models within applications both before and after they are deployed in a production environment.
There are two schools of thought about how best to achieve that goal. The first is to to assume an AI model is just another type of software artifact that can be managed as part of an existing DevOps process. In that context, there is no need for a separate MLOps platform. Conversely, proponents of MLOps contend AI models are built using pipelines created by data engineering teams working in collaboration with data scientists. Developers only become part of the process when an AI model need to be inserted into an application environment. AI models may ultimately need to be incorporated within an application, but the process for building them needs to remain unique and distinct from any other type of software artifact.
Singh says there will always be a need for a separate MLOps platform. However, as development of AI models continues to mature, greater convergence between DevOps teams and data science teams will inevitably be required.