
Tetrate and Bloomberg revealed today they will collaborate on the development of an artificial intelligence (AI) gateway that is based on the Envoy Gateway project launched by the Cloud Native Computing Foundation (CNCF).
The Envoy Gateway project is an open-source effort being led by Ambassador Labs, Fidelity Investments, Tetrate and VMware to provide a simpler method for managing application programming interfaces (APIs). At its core, the project is extending an Envoy API originally developed for Kubernetes environments.
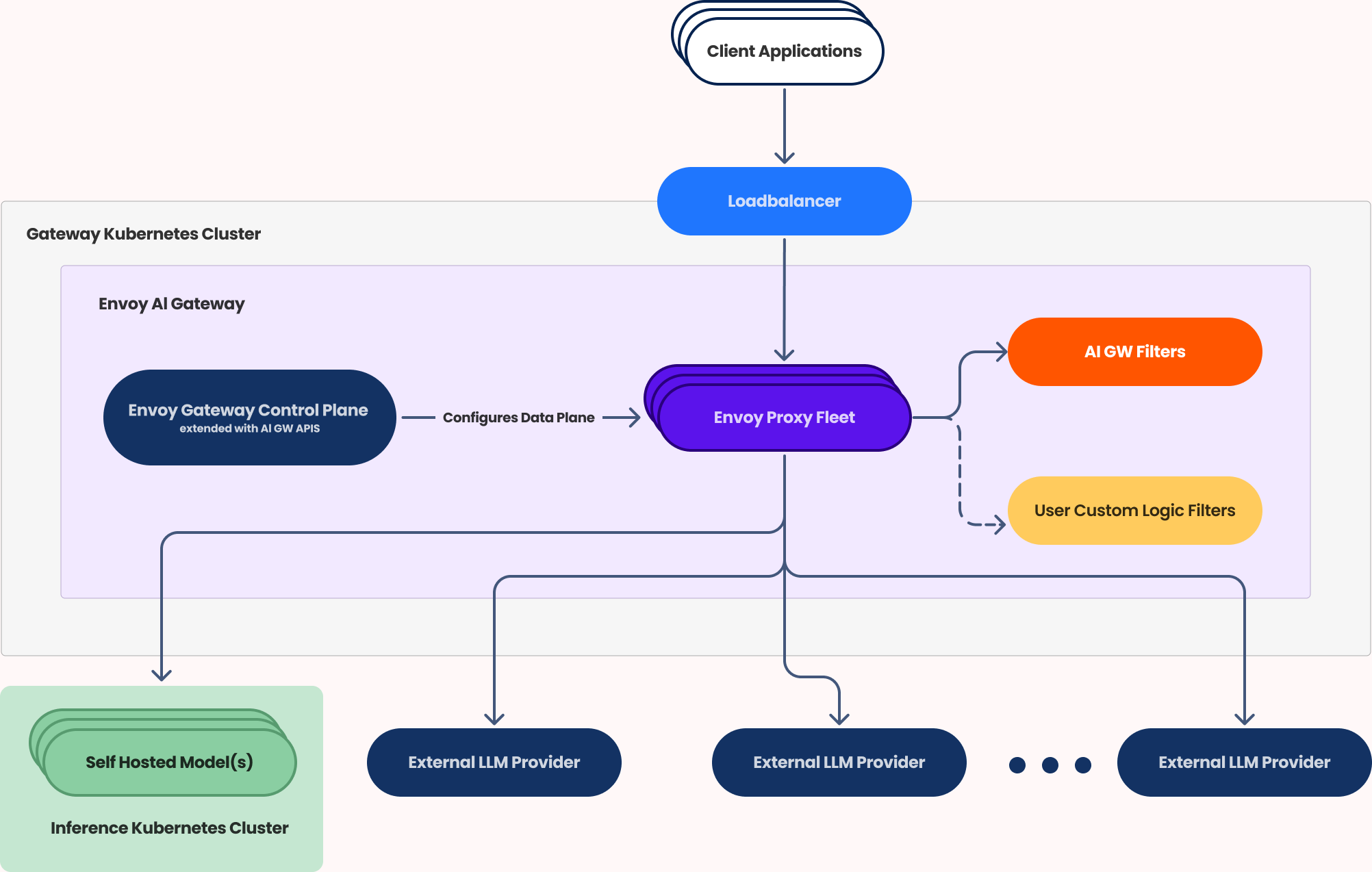
The first features to be included in Envoy AI Gateway will include an application traffic management ability to monitor and control LLM usage via a unified interface through which authorization mechanisms and intelligent fallback options can be invoked should an LLM become unavailable.
Additionally, Tetrate and Bloomberg are making use of KServe as an open-source project that enables serverless inferencing on Kubernetes by providing an interface for machine learning frameworks such as TensorFlow, XGBoost, scikit-learn, PyTorch and ONNX.
Tetrate founder Varun Talwar said, in collaboration with Bloomberg, there is now an effort to use the same capability to invoke multiple large language models (LLMs). That’s critical because, in the AI era, it’s become apparent that organizations will regularly invoke multiple LLMs based on which one has been best optimally trained to perform a specific task, he noted.
At the same time, organizations will need more control over the graphical processor units (GPUs) deployed given their cost and current level of scarcity, noted Talwar.
In fact, over time most organizations will not only find a need to invoke multiple LLMs, but also smaller domain-specific language models that will be deployed across a hybrid IT environment, said Talwar.
Ultimately, the research and development effort led by Tetrate and Bloomberg will be shared with the rest of the open-source community. In the meantime, Bloomberg has a pressing need to prove an AI gateway can be used, to make invoking the APIs that AI models expose much simpler than it is today, noted Talwar.
The Envoy Gateway has been designed to provide a simpler approach than a service mesh that many organizations are today deploying to invoke APIs at scale. The AI Gateway will extend that core capability to make it possible to route requests to multiple AI service providers and models through a single reverse proxy layer that can be invoked via a standard API. Application developers can then use that gateway to, for example, enforce rate limiting, add caching or observe AI workflows.
It’s not clear just how quickly enterprise IT organizations are operationalizing generative AI platforms but the need to mix and match them is already apparent. The challenge now is finding a way to make those LLMs available in a way that reduces the overall level of friction that might otherwise be encountered, noted Talwar.
Not every organization may wind up deploying their own LLM, but they most certainly will be invoking multiple generative AI services. The issue now is making sure they don’t get locked into one service versus another at a time when advances in LLMs continue to be made at a fast and furious rate.