
Ken Lu co-authored this article.
AI is the fastest-growing class of workloads in the cloud. The data it handles is often sensitive and/or regulated, and the models are valuable. Can we better protect AI? Can we rein in AI costs and its environmental impact? Being able to measure workload energy consumption provides awareness, which in turn paves the way for optimization. Confidential computing, special instructions and hardware, in combination with projects such as KEDA and Kepler, can work together to provide all three: Scalability, sustainability and security.
Scalability: Kubernetes is elastic with respect to pod scaling, and offers two options: Horizontal pod autoscaling (HPA), which is mature, and the still-evolving vertical pod autoscaling (VPA). In conjunction with Kubernetes-based Event Driven Autoscaler (KEDA), it is possible to scale any container up or down, even to zero, triggered by one or more input sources. A trigger input could be telemetry, such as energy consumption or the carbon footprint of a workload, which could be negligible if the underlying infrastructure was running on solar power.
Sustainability: Project Kubernetes Efficient Power Level Exporter (Kepler) is a Prometheus exporter that uses eBPF to probe CPU performance counters and Linux Kernel tracepoints that gather data and stats from cgroup and sysfs that are fed into ML models to estimate energy consumption by individual pods, containers and pipelines. Hardware such as GPUs, special purpose accelerators such as crypto and compression solutions like Intel® Quick Assist technology, acceleration instructions for matrix or vector operations such as Intel® AMX and some software libraries that use these and lower precision data representations such as int8 or bfloat16 that can provide energy savings without compromising performance or quality. These savings can be captured in Kepler. What we can measure, we can improve. Such energy metrics can be used to incentivize and guide ML researchers and practitioners to develop and adopt more energy-efficient solutions.
Security: Kubernetes provides access control, policies to enforce container security best practices, service meshes to encrypt inter-service communication, launching images only after signature verification, scanning workloads for CVEs and more to better secure workloads. In addition to these, we now have the option to leverage confidential compute (CC), which extends data protection from at-rest and in-motion to in-use. Confidential Virtual Machine (CVM)-based CC solutions provide a trusted execution environment (TEE) that provides hardware-backed memory encryption and integrity, better protection from privileged processes such as the operating system and hypervisor and supports hardware-rooted attestation.
Three flavors of CVM-based CC solutions are evolving in cloud native. Confidential clusters are Kubernetes clusters where each of the worker nodes run on CVMs. Confidential containers, provided by project CoCo, are individual pods wrapped in a CVM. Third, one may launch a confidential VM workload using KubeVirt. Intel recently open-sourced the confidential cloud-native primitives (CCNP) project to provide trusted primitives across these diverse use cases. It currently provides services to get a quote, a measurement, event logs and attestation with operators and documentation for the same. These can be run as daemon sets when working with confidential clusters or as a sidecar with confidential containers or as a containerized service within a confidential VM workload. The services also support Trusted Platform Modules (TPMs). CCNP can be extended to support CC solutions from other hardware vendors, such AMD, Arm and IBM, to name a few.
Figures 1 and 2 illustrate how one may protect AI models at rest and release keys to a TEE only after it is validated using CCNP.

Figure 1: Encrypting models and controlling access to keys through a key broker service

Figure 2: Application flow to retrieve encrypted model and key
Here’s an example of how scalability, sustainability and security come together to address an oft-encountered AI pipeline use case in retail and surveillance: Identifying objects in video streams. We share a reference solution to this problem at https://github.com/intel/cloud-native-ai-pipeline.
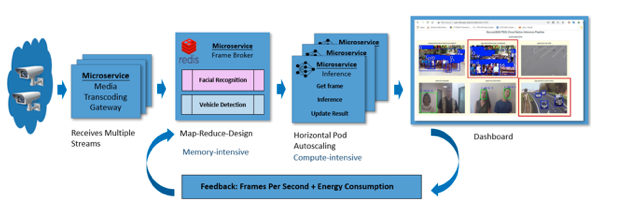
Figure 3: AI Pipeline: Object identification in video streams
AI models can be encrypted and the key released only to verified users; in this case, a TEE that has proved its validity. The model is then decrypted in the context of the TEE, invisible to other users on the platform and used for inference.
The inference stage could benefit from confidential compute to protect the ML models in addition to leveraging special-purpose hardware, instructions and libraries to gain performance with energy savings. A service-level agreement (SLA), specified as some fixed number of frames-per-second (FPS), is a key video processing metric. Early results indicate significant energy savings under identical frame processing rates when using Intel AMX and without. In the context of our inference task, a CPU with acceleration may more than meet our needs. However, ML training tasks, which are more compute-intensive, do benefit from GPU availability.
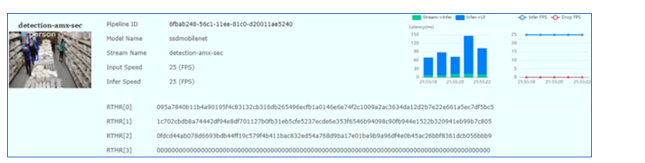
Figure 4: Object detection using confidential compute with matrix processing acceleration. 25 FPS, matching the incoming frame rate.
SLAs of some fixed FPS can be used in conjunction with Kepler’s energy footprint and/or its associated carbon tax via KEDA to control the number of pod replicas. In a hybrid cloud model, workloads can be migrated to infrastructure with a lower carbon tax—such as a data center powered by renewable energy sources such as wind or solar—at any given time. This is particularly attractive for batch processing tasks such as ML training.
The Future: Strong identity is the cornerstone of trust, particularly for collaborative tasks, such as federated learning, where multiple parties join forces to build a model in a distributed manner without disclosing their individual data sets. Examples include a disease detection model using data from patients at different hospitals, developing drug assimilation and toxicity models across different human genomes and developing financial risk profiles using data from across lenders, to name just a few. In these use cases, it is important to establish that each of the collaborators is following the exact same model-building recipe per the binary execution instructions. Innovations leveraging CC hardware-rooted measurements that capture the running container image signatures, along the lines of Container-IMA: A privacy-preserving Integrity Measurement Architecture for Containers, would be valuable.
In the ML context, heterogenous computing, spanning CPUs, GPUS, TPUs, Gaudi and other special purpose accelerators, play a pivotal role in delivering performance at lower power. The Linux Foundation announced in mid-September 2023 the creation of the Unified Acceleration Foundation (UXL), a cross-industry group committed to delivering an open standard accelerator programming model that simplifies the development of performant, cross-platform applications. Intel’s successful OneAPI is the genesis of UXL.
Building on UXL for ML and all long-running compute tasks, it is valuable to build workload energy models using Kepler. Integrating energy metrics in projects like KubeFlow for MLOps would further bring sustainability to the forefront. Such energy models could also guide Kubernetes schedulers to explore heterogeneous resource allocation in a cascading manner to conserve energy. Finally, to better stem climate change, specifically for workloads lacking stringent latency needs, developing multi-cloud carbon footprint-minimizing orchestration would be compelling.
To hear more about cloud-native topics, join the Cloud Native Computing Foundation and the cloud-native community at KubeCon+CloudNativeCon North America 2023 – November 6-9, 2023.