
Couchbase has extended the operator it created for deploying its namesake document database on Kubernetes clusters to add support for autoscaling to ensure performance levels in addition to enabling IT teams to employ Fluent Bit to audit logs.
Version 2.2 of the Couchbase Autonomous Operator (CAO) for Kubernetes enables IT teams to independently scale storage without having to restart a Kubernetes cluster. Teams can also modify remote cluster identification and authentication settings.
This update also provides IT teams with more control over upgrades, the ability to customize server groups, tighter integration with Prometheus and the ability to automatically allocate Kubernetes resources based on policies defined by an IT team.
Anil Kumar, director of product management for Couchbase, said over the last year, Couchbase has been extended to employ a single Kubernetes operator to deploy and manage both its database and a variety of complementary third-party tools such as Prometheus monitoring software or the Istio service mesh.
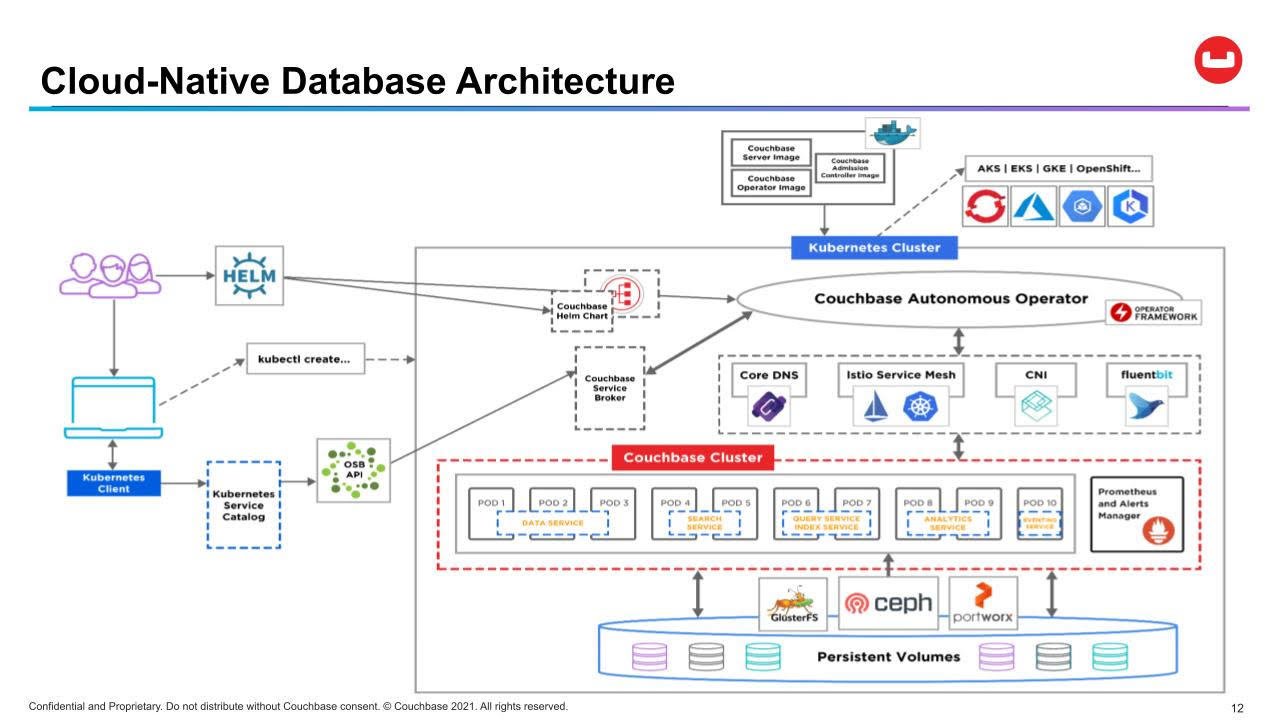
CAO 2.2 also provides improved integration with Helm Charts for IT teams that prefer to use that tool rather than an operator, noted Kumar.
Finally, Couchbase has enhanced both the security and backup and recovery tools that come with the database.
Originally developed by CoreOS, operators are emerging as a class of tools that make Kubernetes environments more accessible to the average IT administrator. Most vendors these days have made available an operator that makes it simpler to deploy and update both their offering and the Kubernetes cluster it is deployed on. Couchbase is now extending that concept to include all the tools that IT teams need to deploy, as well.
Some IT organizations are even taking the concept of an operator a step further by creating their own instance of an operator, through which they can manage the specific application and associated infrastructure that they have elected to deploy on top of a fleet of Kubernetes clusters.
One way or another, Kubernetes environments are becoming more accessible to the average IT team. In an ideal world, every IT organization would have a small team of site reliability engineers (SREs) that could automate the management of Kubernetes environments at scale. SREs, however, are hard to find and comparatively expensive the hire. Operators make it possible for the average IT administrator to take on specific tasks either on their own or in collaboration with an SRE.
Finding a way to strike a balance between those skillsets will become increasingly critical as more data is stored on Kubernetes clusters. While many IT teams still prefer to run stateless applications on Kubernetes clusters that store data outside of the cluster, more organizations are starting to deploy stateful applications that need to access a database on their Kubernetes cluster as part of an effort to unify the management of compute and storage.
Most IT teams, of course, will find themselves managing a mix of stateless and stateful applications running on a larger number of Kubernetes clusters. The first step toward bringing some order to that potential chaos will be determining what mix of operators to rely on to streamline the management process.