
VMware Makes Persistent Data Available Via Kubernetes API
VMware announced today general availability of a vSAN Data Persistence Platform, through which Kubernetes clusters will be able to access data stored in VMware platforms.
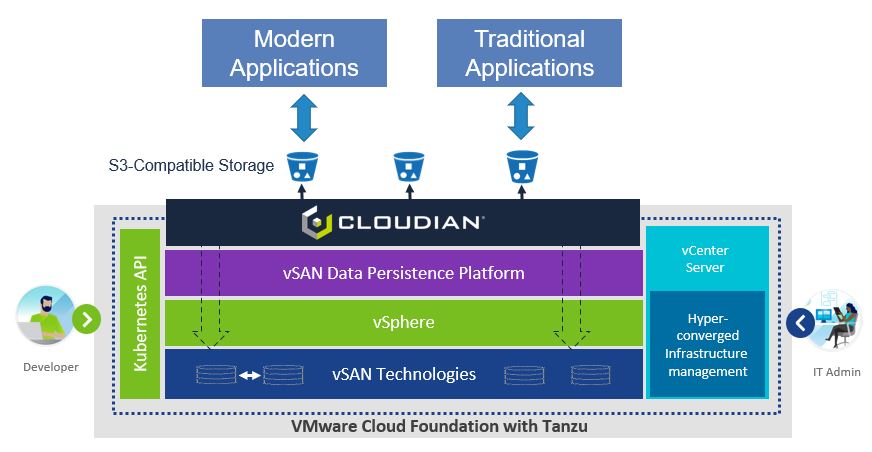
Developed in collaboration with Cloudian and MinIO, the vSAN Data Persistence Platform adds a layer of software on top of vSAN that makes it possible to access data residing in an object-based storage system that is compatible with the S3 application programming interface (API) defined by Amazon Web Services (AWS).

At the same time, VMware is adding a vSAN HCI Mesh through which storage clusters can now be disaggregated from servers. That approach makes it possible for IT teams that have deployed Kubernetes clusters to access the vSAN Data Persistence Platform using standard Kubernetes APIs.
Sheldon D’Paiva, director of product marketing for VMware, says the goal is to make data already residing in VMware environments accessible to both legacy monolithic applications running on VMware virtual machines and microservices-based applications running on Kubernetes. That approach reduces the total cost of IT, because there’s no need to deploy a separate storage system for applications running on Kubernetes, says D’Paiva.
In many cases, the data that microservices-based applications need to access is already residing in storage systems that vSAN can readily access, D’Paiva says. Providing access to that data without using vSAN would necessitate moving data from one storage system to another, he adds.
Cloudian is leveraging that capability to add support for VMware Cloud Foundation (VCF) with VMware Tanzu, the distribution of Kubernetes provided by VMware, to its HyperStore object storage platform. VCF is a suite that combines VMware vSphere, vSAN and NSX network virtualization software into a single offering. The vSAN Data Persistence Platform is being made available as part of an update to VCF.
Jon Toor, chief marketing officer for Cloudian, says this capability will play a crucial role in not only making it easier to deploy stateful applications on Kubernetes clusters, but also scale the resources up and down as required.
In general, VMware is making the case for running, within the context of an IT platform, any class of application that can be automated using frameworks such as vRealize. The company today also released an update to vRealize that, among other capabilities, provides the ability to create, update, read and delete property groups with predefined data. The latest edition of vRealize also adds support for additional analytics based on machine learning algorithms to make it easier to discover errors and anomalies in complex IT environments.
Of course, introduction of Kubernetes into existing IT environments is now one of the major root causes of that increased complexity. Managing monolithic applications on-premises and in the cloud is hard enough. Now, there are multiple classes of stateless and stateful applications based on microservices being deployed alongside those monolithic applications. It’s not clear just how much complexity any given IT organization can effectively absorb, but without reliance on automation, most IT teams are going to bite off a lot more than they can chew.
